Dining-Philosophers Problem

- 내용
- 5명의 철학자들은 평생 정해진 원탁의 자리에서 살아야 함
- 철학자들이 하는 일은 철학하는 것과 음식을 먹는 것 두 가지뿐이라고 모델링
- 접시는 각자 하나씩 총 5개가 있고 젓가락은 접시 양 옆에 한 짝씩 존재하여 이 또한 5개
- 식사를 하는 철학자는 접시 양 옆의 젓가락을 들고 식사를 할 수 있음
- 한 사람씩 식사를 하고 싶다면 순서대로 젓가락을 사용할 수 있지만 동시에 모든 사람이 배가 고파진다면 젓가락이 부족
- 만약 모든 철학자들이 젓가락을 한 짝씩 들고 있다면 모두 식사를 하지 못하게 될 것
- 각자의 철학자에 맞춰서 구성을 해본다면(해결 방안)

- 실제 구현

- 잘 생각해볼 것
임계 영역 프로그래밍
- 기본 코드

- 두 개의 스레드로 동작
- 메인 프로그램

- 두 스레드를 생성
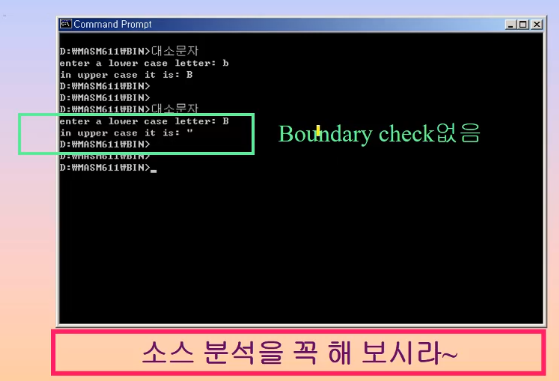
- 앞의 코드 for(;;)에 sleep(1) 함수를 추가해 보자 - 그 순간에 스케줄링을 시켜줌

- 임계 영역(Critical Section) 접근 동기화

- g_var라는 int형 변수를 선언한 후 사용
- 첫 번째 스레드는 g_var를 1로 만들고 Sleep(1)을 한 후 g_var 값을 출력

- 두 번째 스레드는 g_var를 2로 만들고 Sleep(1)을 한 후 g_var 값을 출력
- 원하는 결과

- 실제 결과
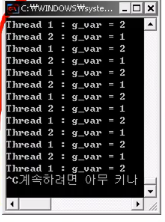
- Sleep을 하는 동안 공유 변수 g_var의 값이 다른 스레드에서 바뀌기때문
- Sleep을 빼고 확인해볼 것
유저 모드의 동기화
- 임계 구역 기반의 동기화
- 화장실에 걸어 놓은 열쇠(비유)

- CRITICAL SECTION의 변수를 설정(화장실 열쇠) - CRITICAL_SECTION gCriticalSection;
- 변수 초기화(열쇠 걸어 놓음)

- Critical Section의 변수를 사용하여 임계 영역으로 들어감.(화장실 열쇠를 획득)

- 키를 반환하고 임계 구역을 빠져나옴.(화장실 열쇠를 반환, 다시 걸어놓음)

- 형식

- 임계 영역에 하나라도 들어가 있다면 나머지 프로세스들은 대기
- 실제 프로그램 코드
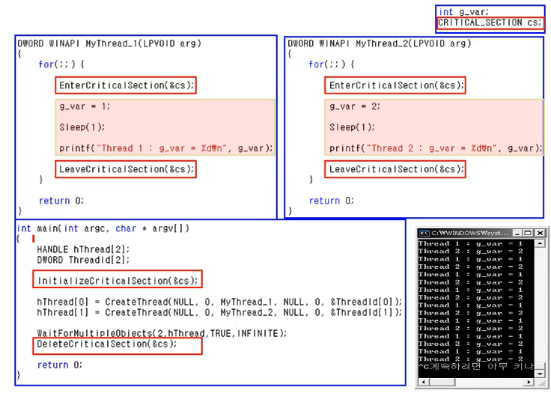
- 각 스레드의 for문 안의 내용을 critical section으로 묶음
- 임계 영역에 sleep이 있으므로 스케줄링은 할 수 있으나 다른 스레드에 의해 값은 바뀌지 않음
- LeaveCriticalSection 이후에 여러 코드를 추가하여 어떻게 실행되는지를 확인해보자
커널 모드의 동기화
- 뮤텍스(Mutex) 기반의 동기화

- 구조는 동일
- 사용하는 함수의 이름이 달라짐
- 운영체제가 개입 - wait 할 때, CPU를 사용하게 할 수도 있고 안 할 수도 있음 -> 유저 레벨에서 할 수 없었던 일을 할 수 있음
- 세마포어(Semaphore) 기반의 동기화


- 세마포어(세마포어 오브젝트)를 생성하는 함수

- 시뮬레이션


- 한 테이블에는 1명씩 총 10명이 동시에 식사를 할 수 있음
- 각 사람마다 초기값을 가지고 있음(식사시간)
- 치우는 시간은 없다고 가정
- 이러한 프로그램을 이용하여 여러 가지 요소들을 예측하여 최적의 환경을 만들어낼 수 있음(아르바이트생의 수, 일을 해야 하는 시간 등)
Deadlocks
- The Deadlock Problem
- 한 프로세스가 자원을 요청했을 때, 그 자원을 사용할 수 없게 된다면 대기상태가 됨
- 대기 중인 프로세스가 요청한 자원들이 다른 대기 중인 프로세스에서 점유되어 있을 때, 이 프로세스 상태를 변경시킬 수 없는 경우를 교착상태라고 함
- 두 개의 프로세스가 한 개의 구동기를 점유한다고 가정
- 만약 프로세스가 다른 구동기를 요청한다면 두 개의 프로세스는 교착상태가 됨

- 어떤 한 자원을 가지고 있고 다른 자원을 또 가지려고 대기
- 두 자원을 다 가지면 어떤 일을 하겠다는 것
- 두 프로세스가 각각 자원 하나씩을 가지게 된다면 계속 대기해야 하는 상황
- Bridge Crossing Example(외나무다리)

- 마주오는 두 개의 자동차를 생각해보자
- 하나의 차량이 돌아가기 전까지는 누구도 빠져나갈 수 없게 됨
- 교착상태 -> 기아상태가 발생
- System Model
- 시스템은 경쟁할 프로세스들 사이에서 유한한 수의 자원들로 구성
- 자원은 R1~Rm까지 존재(CPU cycle, memory space, I/O devices 등)
- 이들 각각 자원들은 동일한 다수의 인스턴스를 가지고 있음(Ri has Wi instances)
- 프로세스는 자원을 사용하기 전에 요청을 해야 함
- 사용한 후에는 해제해야 함
- Deadlock Characterization
- 아래 네 가지 특징을 모두 가지고 있을 경우 교착상태 - 교착상태일 때 이러한 특징을 가지고 있음(필요조건 o, 충분조건 x)
- Mutual exclusion(상호 배제) : 하나의 프로세스는 한 번에 하나의 자원만 사용할 수 있도록 되어있음
- Hold and wait(점유 및 대기) : 최소한 하나의 자원을 점유하고 있는 프로세스가 있는데, 이 프로세스는 다른 프로세스에 의해 점유된 다른 자원을 추가로 얻기 위해서 기다리고 있는 상태
- No preemption(비선점) : 점유된 자원은 강제적으로 해제될 수 없고 점유하고 있는 프로세스가 그 테스크를 종료한 후에 자원이 저절로 해제됨
- Circular wait(순환 대기) : 대기하고 있는 프로세스의 집합에서 P0 -> P1, P1 -> P2 ... Pn-1 -> Pn, Pn -> P0로 점유한 자원을 대기하는 것이 고리를 형성하여 순환하는 상태
- Resorce-Allocation Graph(자원 할당 그래프)
- 교착상태는 시스템 자원 할당 그래프라는 방향 그래프로 표명할 수 있음
- Vertices(정점)와 Edges(간선)로 이루어져 있음
- V(정점)는 2가지 형태로 구성되어 있음 - P(시스템 내 모든 프로세스들의 집합), R(시스템 내 모든 자원들로 이루어진 집합)
- Request edge - Pi가 Rj를 요청하는 요청선(Pi -> Rj)
- Assignment edge - Rj가 Pi에 할당된 것을 의미하는 할당선(Rj -> Pi)
- 그림으로 나타내면

- 프로세스는 원
- Resource는 사각형인데 안에 작은 사각형이 있는 것은 여러 디스크(D, C, E 등)가 할당된 것을 의미
- 프로세스 Pi가 자원 Rj를 요청하고 있는 것
- Rj이 가지고 있는 것들 중 하나가 Pi에 할당(Rj안의 인스턴스 하나가 할당)
- 3개의 프로세스의 예

- P1은 R1을 요청
- R1의 인스턴스는 P2에 할당
- P2는 R3를 요청
- R3의 인스턴스는 P3에 할당
- R2의 인스턴스는 P1과 P2에 할당
- 순환 그래프가 그려지지 않는다면 교착상태가 아님
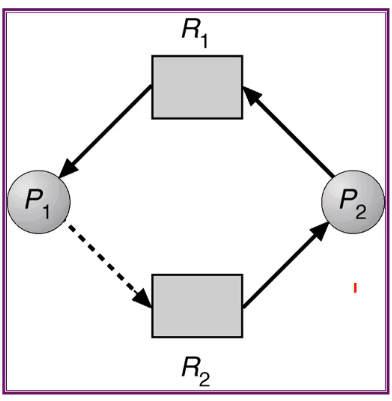
- 또 다른 예

- P3가 R2에 자원을 요청하지만 R2의 자원을 P1과 P2가 사용 중
- P3는 R2에 자원이 돌아올 때까지 대기
- P1과 P2도 마찬가지로 R1과 R3에 각각 자원을 요청하였으나 이미 사용 중이기 때문에 대기하는 중
- 따라서 3개의 프로세스가 전부 기다리게 됨 -> 교착상태
- 또 다른 예 2

- P1 -> R1 -> P3 -> R2 -> P1으로 순환이 형성 -> 교착상태인가?
- P4나 P2가 끝나고 자원을 돌려주면 돌려받은 자원을 P1과 P3에 할당할 수 있으므로 교착상태는 생기지 않음
- 순환이 형성된다고 해서 무조건 교착상태는 아님
- Basic Facts
- 그래프가 주기를 가지지 않으면 교착상태는 존재하지 않음
- 그래프가 주기를 가지면
- 자원이 인스턴스를 하나만 가지고 있다면 반드시 교착상태
- 자원이 인스턴스를 여러 개 가지고 있다면 다른 프로세스가 해제할 경우 돌려받은 자원을 할당해 줄 수 있으므로 교착상태에서 벗어날 수 있음 -> 가능성은 있으나 항상 교착상태는 아님
- 교착상태를 처리하는 방법
- 시스템이 교착상태가 되지 않도록 보장하는 프로토콜을 만드는 방법
- 시스템이 교착상태가 되도록 허용한 후에 이를 회복하는 방법을 만듦
- 이러한 문제를 무시하고 교착상태가 생기지 않는다고 생각, 운영체제에 교착상태가 절대 발생하지 않는 척 -> 교착상태가 발생하지 않도록 운영 프로그램 개발자가 알아서 사용
- 교착상태의 예방(Prevention)
- 아래 네 가지 중 하나를 안생기게 하면 교착상태에 빠지지 않음
- Mutual Exclusion : 공유 자원을 요청하지 않음, 비공유 자원을 전제로 함
- Hold and Wait : 점유 대기 조건이 시스템에서 발생하지 않으려면, 프로세스가 자원을 요청할 때마다 다른 자원들을 점유하지 않도록 보장해야 함 -> 자원 이용률이 낮아짐

- No Preemption(비선점)

- Circular Wait(순환 대기) : 모든 자원 형태들에게 전체 순서를 부여하고, 각 프로세스가 열거된 상태에서 순서(오름차순)를 정해 자원을 요청하는 프로토콜을 사용하는 것
- Deadlock Avoidance(교착상태 회피)
- 자원을 요청하는데 필요한 추가의 앞선 정보(additional a priori information)를 요청하는 알고리즘 작성으로 교착 상태를 회피

- Safe State(안전 상태)
- 특정한 순서대로 각 프로세스의 자원을 할당할 수 있게 되었을 때, 교착상태를 방지할 수 있으면 이것을 안전 상태라고 함
- 하나의 프로세스가 이용 가능한 자원을 요청할 때, 시스템은 즉각적인 자원 할당이 안전상태를 벗어나는 것을 매번 결정하게 됨
- 모든 프로세스의 안전 순서(안전상태를 유지하는 순서)가 존재하면 이 시스템은 안전 상태에 있다고 말할 수 있음


- 시스템이 안전 상태에 있다면 교착상태는 아님
- unsafe 하다면 교착 상태가 생길 수 있음
- 시스템이 불안정 상태로 들어가지 못하도록 하는 것이 교착 상태 회피 알고리즘 -> 시스템이 항상 안전 상태에 머무르도록 하는 것
- 안전한 상태가 있는가를 살펴보자

- 자원은 총 12개
- P0는 최대 10개를 요청할 수 있고 5개 할당
- P1은 최대 4개를 요청할 수 있고 2개 할당
- P2는 최대 9개를 요청할 수 있고 2개 할당
- 3개가 남아있음
- 만약 P0~2가 동시에 최대 수요량만큼을 요청했다면 자원이 부족해짐 -> 교착상태
- 이 상황에서 P0가 나머지 수요량인 5개의 자원을 요청한다면 2개가 부족하므로 교착상태가 발생
- 최대는 넘지 않게 각각의 요구를 만족할 수 있는 순서가 있느냐를 봐야 함
- P0는 5개가 필요하고 P1은 2개, P2는 7개가 필요하므로 나머지 자원(3개)을 할당했을 때 최대 수요를 만족하는 P1에 우선적으로 자원을 할당
- P1이 끝났다면 남은 자원은 5개가 되어 P0에 모두 할당 -> 최대 수요를 만족
- 마지막으로 남은 자원 10개를 P2에 7개 할당 -> P2 만족
- 이 순서로 할당하지 않는다면 교착 상태가 발생할 수 있음

- Resource-Allocation Graph Algorithm
- 앞서 한 것들을 요청 가능선, 요청선, 할당선 등으로 구체화시켜 나타냄

- 점선 : 요청 가능선 -> 요청이 되어 자원 할당을 받는다면 할당선으로 바뀜
- 실선(R1 -> P1) : 할당선
- 실선(P2 -> R1) : 요청선
- Banker's Algorithm
- 앞의 리소스로 설명한 것을 Multiple instances에 대해 어떻게 이 알고리즘을 바꿔야 하는지를 정리한 것
- 자원 할당 그래프의 알고리즘은 다수개의 자원 유형을 갖는 시스템에서 적용할 수 없음
- 다수개의 자원 유형을 갖는 시스템에서 적용하기 위한 알고리즘
- 새로운 프로세스가 시스템에 들어가면 필요로 하는 각 자원 형태들의 최대수를 미리 선언하고 알고 있어야 함
- 프로세스가 자원을 요구할 때, 시스템은 자원을 할당한 다음에 안전상태로 남아있는지를 결정해야 함
- 안전상태로 남아있으면 할당하고 그렇지 않으면 다른 프로세스들이 자원을 충분히 해제할 때까지 대기
- 은행가 알고리즘은 은행이 모든 고객의 수요를 충족시킬 수 있도록, 현금을 할당하는 데 기인한 알고리즘
- Data Structures for the Banker's Algorithm

- 여러 개의 프로세스가 여러 개의 자원들을 필요로 함
- 필요로 하는 자원들을 어떻게 관리를 할 수 있는지 -> 안전한 상태를 유지할 수 있는지
- Safety Algorithm(꼭 해볼 것! 시험에 매번 나옴)

- 어떻게 유지가 되는지를 잘 보면 됨
- 예시

- 프로세스는 5개
- 자원은 세 가지
- 현재 각 프로세스가 할당받은 자원들과 최대로 할당받아야 하는 양, 남은 자원의 양
- 꼭 해볼 것

- Resource-Request Algorithm for Process Pi - 추가 요청

- 예시) P1이 (1,0,2)를 추가로 요청했을 경우 -> 어떻게 업데이트를 할 것인가

- 남아있는 자원(3,3,2)이 (2,3,0)으로 줄어듦
- Deadlock Detection
- 시스템이 교착상태로 들어가도록 하는 것 까지는 허용
- 교착상태가 발생했는지 파악하기 위해서 시스템 상태를 탐지
- 탐지를 했다면 회복(Recovery)
- Single Instance of Each Resource Type

- Resource-Allocation Graph를 Wait-for Graph로 단순화 -> 교착상태가 생겼는지를 한눈에 볼 수 있음(순환 고리 형성)

- Several Instances of a Resource Type

- 교착상태가 발생하고 여러 개의 인스턴스가 있을 경우의 설명
- Detection Algorithm

- 표현법이 Need가 아닌 Request가 됨
- Detection-Algorithm Usage - 언제 탐지 알고리즘을 호출할 것인가?
- 교착 상태 발생 빈도수
- 교착 상태가 발생했을 때, 영향을 받는 프로세스의 수
- 교착 상태가 자주 발생하면 탐지 알고리즘도 더 자주 호출해야 함 -> 운영체제가 하는 일이 많아져서 효율이 떨어짐
- Recovery from Deadlock : Process Termination
- 순환 대기를 탈피하기 위해서 단순히 프로세스 하나를 중지시키는 것
- 교착상태 프로세스들로부터 자원을 선점하는 것

- Recovery from Deadlock : Resource Preemption
- 자원 선점에 의한 방법 - 잘 읽어볼 것

- Combined Approach to Deadlock Handling(복합적인 방법)

'운영체제' 카테고리의 다른 글
| [13주차]Bakery Algorithm (0) | 2019.06.01 |
|---|---|
| [12주차]chapter 6 : Process Synchronization(프로세스 동기화) (0) | 2019.05.21 |
| [11주차]간단한 어셈블리 프로그래밍 (0) | 2019.05.14 |
| [10주차]System Call의 이해 - 어세블리어 (PC버전) (0) | 2019.05.10 |
| Chapter 5 - CPU Scheduling(9주차) (0) | 2019.04.30 |