- Instance : 프로그램을 실행하기 위해 필요한 메모리와 프로세스 구조
- PMON : LISTENER에게 서비스에 대한 정보를 전달
- MMON : 한 시간에 한 번씩 스냅샷을 AWR에 기록
- 데이터베이스는 테이블스페이스 단위로 나뉘어 있음
- sga, pga 메모리 관리 방식 확인 : show parameter target -> memory_target
- memory_target : AMM(Automatic Memory Management, 11g ~ )의 기능을 쓰는지 안 쓰는지(안 쓰면 0)
- SGA + PGA = memory_target(합해서 정한 크기를 알아서 씀)
- pga_aggregate_target : PGA를 이 값 안에서 사용, SGA와 별개의 공간
- sga_target : ASMM(Automatic Shared Memory Management, 10g ~ ) -> 자동으로 공유 메모리 관리(정한 값 내에서) -> PGA와 별개, 부족한 공간에 빌려줄 수도 있음
- v$memory_dynamic_components : 저장공간이 어디에 할당되어 있는지 확인 가능
- 옵티마이저 이어서
- 옵티마이저가 필요한 이유 : 데이터가 어떻게 저장되어 있느냐에 따라 실행계획을 찾을 때 더 빠른 방법을 찾을 수 있음
- 변형기 : 내가 쓴 쿼리문을 분석하여 동일한 결과를 가지는 가장 빠른 쿼리로 변경
- 예측기 : 선택성 = 조건을 충족하는 행 수 / 총 행 수
- cardinality = 선택성 * 총 행 수
- 비용(cost) : (단일 블록 I/O 비용 + 다중 블록 I/O 비용 + CPU 비용) / 단일 블록 읽기 시간
- OPTIMIZER_MODE
- ALL_ROWS
- FIRST_ROWS : 화면에 보이는 만큼의 데이터를 우선으로 불러옴, 페이지를 넘길 때마다 로딩
- FIRST_ROWS_n
- OPTIMIZER_DYNAMIC_SAMPLING : 실행계획을 작성하는 시점에서 샘플링 방식으로 데이터를 모음
- OPTIMIZER_INDEX_CACHING : 인덱스들이 얼마나 캐싱되는지, default 값은 0 -> 값을 늘리면 그만큼 인덱스 코스트가 줄어듦
- OPTIMIZER_INDEX_COST_ADJ : default 100, 인덱스 cost를 몇 퍼센트로 생각하는지 -> 줄이면 줄인 만큼 인덱스를 더 선택할 수 있음
- OPTIMIZER_FEATURES_ENABLED : 오라클의 버전을 이 값 이하로 고정, 높은 버전을 믿을 수 없는 경우 설정
- db_file_multiblock_read_count : 한 번에 몇 개의 블록을 한 번의 I/O로 읽을 것인지 -> 전체 테이블 읽기를 했을 때, I/O횟수를 줄이기 위함
- 실행 계획
- SQL 문의 실행 계획은 직렬 계획에 대한 행 소스라고 하는 작은 구성 요소로 이루어져 있음
- EXPLAIN PLAN 명령 : 옵티마이저 실행 계획 생성 -> 계획을 PLAN_TABLE에 저장
- explain plan
- for
- select ename, sal from emp where deptno=10;
- plan_table에 계획 저장(확인 가능) -> plan table은 모든 유저에 대한 explain plan문 출력을 보관하기 위해 자동으로 global 임시 테이블(temporary table)로 생성
- $ORACLE_HOME/rdbms/admin/utlxplan.sql 스크립트를 사용하여 PLAN_TABLE을 직접 생성할 수 있음
- dbms_xplan.display(plan 테이블, statment_id, format)
- select * from table(dbms_xplan.display);

1) EMP_DEPTNO_IX를 읽음
2) access("DEPTNO"=10)은 위의 인덱스에서 DEPTNO가 10인 것을 찾았다는 의미
- ANALYST라는 직업을 가진 사원 정보

- SQL developer에서도 확인 가능

- plustrace role을 부여하면 어느 유저든 autotrace가능
- autotrace의 기능
- sql문장의 실행결과를 보여줌
- 실행 계획(explain plan과 동일)을 보여줌
- 실행 통계를 보여줌
- set autot traceonly exp : 실행 계획만 보여줌
- set autot traceonly statistics : 통계만 보여줌
- set autot on explain : 결과와 계획만 보여줌
- set autotrace on statistics : 실행결과와 통계만 나옴
- Statistics(통계)

- recusive calls
- db block gets
- consistent gets -> 값이 있다면 logical read
- physical reads
- Dynamic Performance 뷰 간 링크
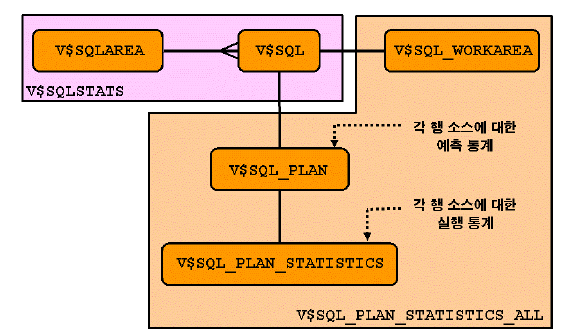
- v$sql_plan : plan_table과 마찬가지로 라이브러리 캐시에 있는 커서에 대한 실행 계획을 검사하는 방법을 제공, 메모리와 관련된 내용이 더 많음 -> 직접 실행한 것이 아닌 예측
- v$sql : sql문이 저장
- v$sql_plan_statistics : 각 행 소스에 대한 실행 통계
- v$sql_plan_statistics_all : 예측 통계와 실행 통계 둘 다 확인 가능
- 라이브러리 캐시의 실행 통계, 계획을 가져옴
- select 문장 실행
- select * from table(dbms_xplan.display_cursor); -> dbms_xplan.display(sql_id, child_number, option) 모두 null을 넣음(option : typical) -> 마지막으로 실행한 sql문장을 typical로 보겠다는 의미
- cursor는 메모리를 의미

- basic

- iostats + memstats = allstats
- gather_plan_statistics

- A(Actual)-Rows : 실제 행
- A-Time : 실제로 걸린 시간
- /*+ gather_plan_statistics */ : 힌트 -> 문장 레벨의 실행 통계를 활성화
- sort
- select * from emp order by sal; -> sort가 일어남
- xplan 실행
- table access full

- xplan_all - sort

- dba권한이 없는 scott user에서 xplan 확인
- sys에서 grant select on v_$session to scott;
- grant select on v_$sql to scott;
- grant select on v_$sql_plan_statistics_all to scott;
- scott 접속
- 위의 과정 확인 가능
- AWR에 저장된 plan 확인 - dbms_xplan.display_awr
- SQL Monitoring : 현재 실행 중인 sql문이 어느 정도 실행되었는지 확인 가능
- sql trace : 여러 sql문의 실행 계획을 비교할 수 있음, 비슷한 업무를 하는 유저들의 실행계획도 합쳐서 비교 가능(튜닝 대상을 뽑아냄)
Optimizer 연산자
- SQL Trace 사용 절차
- trace on : alter session set sql_trace = true;
- select * from emp e, dept d where e.deptno=d.deptno;
- trace off : alter session set sql_trace = false;
- ! tkprof /u01/app/oracle/diag/rdbms/orcl2/orcl2/trace/orcl2_ora_7144.trc output.txt sys=no -> 트레이스 파일을 해석해줌, 시스템이 한 것은 보이지 않게 설정
- output.txt를 읽어본다
- 3단계로 실행하는 실행 단계에 따라 어떻게 실행이 되었는지 자세히 쓰여있음
- tkprof 정렬 옵션

- Table Access
- 전체 테이블 스캔

- 다중 블록 읽기 수행 - HWM아래의 모든 형식 지정된 블록을 읽음
- 많은 양의 데이터를 처리하는 경우 인덱스 범위 스캔보다 빠름
- full table scan이 일어나는 경우
- select * from emp; -> 14줄
- select * from sales; -> 매우 많은 데이터(913004 줄)
- xplan 확인 -> full table scan
- sales에는 5개의 index가 존재(promo_id, cust_id, time_id, channel_id, promo_id)
- 일치하지 않는 조건을 주어 검색 : select * from sales where amount_sold>100000;
- index가 없는 경우
- index가 있더라도 낮은 선택성 필터(혹은 필터 없음)라면 index를 읽지 않고 cost가 낮은 full table scan을 함
- 작은 테이블
- 높은 병렬도
- 전체 테이블 스캔 힌트 : FULL -> select /*+ FULL (emp) */ ...
- FILTER 연산은 데이터 추출 시 필터링이 일어나고 있음을 알려주는 SQL ROW 연산
- WHERE 조건 절에서 인덱스를 사용하지 못할 때 발생
'Oracle > SQL Tuning' 카테고리의 다른 글
| Partitioned table (0) | 2020.02.04 |
|---|---|
| subquery (0) | 2020.01.31 |
| 조인 연산자 (0) | 2020.01.30 |
| Optimizer - 2 + 실행 계획 2 (0) | 2020.01.21 |
| Resumable + Tuning - 1 (0) | 2020.01.17 |