Background
- 야구 : 20명 정도의 선수들이 시합 -> 각자의 역할이 있음(투수가 공을 던져야 시작, 타자가 공을 치거나 포수가 공을 받음, 공이 어느 방향으로 가느냐에 따라 달라짐)
- 각 선수들을 스레드로 보면 각 스레드들은 독립적으로 하는 일이 정해져 있음
- 스레드들 간의 일부 순서가 있고 상호 순서가 지켜져야만 한다.
- 시스템 내의 상호 협조 프로세스 -> 다른 프로세스 실행에 영향을 받음, 주소 공간을 공유하거나 파일에 의해서 데이터의 공유가 허용됨
- 공유 데이터에 대한 동시 접근은 데이터의 불일치로 이어짐 -> 반드시 해결해야 됨
Bounded-Buffer

- Producer process
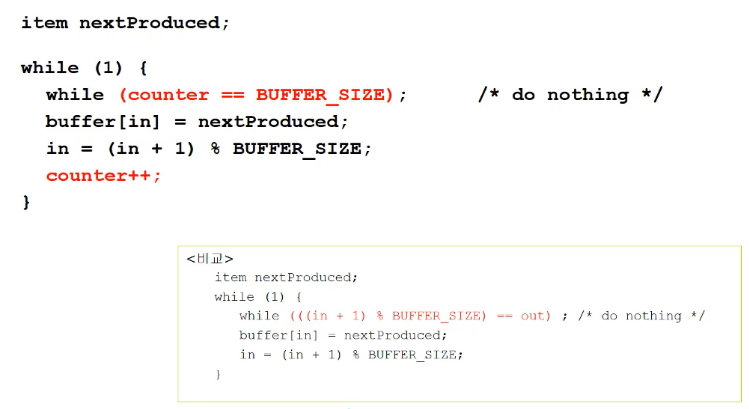
- in과 out이 같은지를 비교했을 때와 달리 정해진 크기의 BUFFER_SIZE와 같은지를 비교하도록 바꿨음
- count변수로 loop를 반복시킴
- Consumer process

- 값을 꺼낼 때 counter를 줄임 -> 포인터 대신 개수로 비교
- 수정된 알고리즘에는 counter라는 공유 변수가 있음
- 두 프로세스는 counter값을 변화시키면서 사용, 비교
- 어느 한순간의 counter가 5라고 가정
- 두 프로세스가 한 번씩 counter에 접근한다면 5->6->5로 값이 변하는 것이 맞음
- 그러나 count++와 count--는 CPU입장에서 하나의 명령인가?
- assembly에서 본 count++
- register1 = counter -> CPU가 값을 레지스터에 읽어옴
- register1 = register1 + 1 -> 그 레지스터 값을 1 증가시킴(아직 counter값은 5)
- counter = register1 -> counter에 6을 저장
- count--
- register2 = counter -> CPU가 값을 레지스터에 읽어옴
- register2 = register2 - 1 -> 그 레지스터 값을 1 감소시킴
- counter = register2 -> counter에 레지스터값을 저장
- 두 프로세스를 동시에 실행시켰다면 어셈블리에서 총 6개의 명령이 실행됨 -> 이것들이 무조건 순서대로 실행이 되는가? (x)
- 엄청나게 많은 프로세스의 사용이 반복된다면 정말 우연히도 6개의 명령이 섞일 수도 있음

- counter를 증가시키는 producer의 프로세스가 진행되는 중에 counter의 값을 바꾸기 전에 consumer의 프로세스가 실행되어 버림
- counter의 값이 6? 4? 나중에 바뀌는 값으로 들어가 버림 -> 오류 발생(counter를 다루는 명령어가 atomic하지 못했다.)
Race Condition
- 위의 문제점을 레이스 컨디션이라고 함 -> 한 프로세스에서만 접근하도록 만들어야 한다.
- 분리할 수 없는 명령이라고 생각하는 것이 섞이지 않도록 나누는 것(동기화)

Critical Section Problem(임계 영역)
- 두 개의 프로세스로 이루어진 시스템
- 각 프로세스는 임계 영역이라는 code segment내에 가짐
- 이 임계 구역은 공유 데이터를 처리하는 각각의 프로세스가 가지는 것
- 한 프로세스가 공유데이터를 처리하는 동안 다른 프로세스가 접근할 수 없는 구역
- 프로세스가 협조할 수 있도록 프로토콜을 설계
- 각 프로세스는 임계 구역에 진입하기 위한 허가권을 운영체제에 요청
- 진입 구역, 임계 구역, 출구 구역, 자유구역으로 나누고 그 구역에 맞게 처리해줌

- 위와 같이 구역을 나눠서 생각
- 임계 구역에 해당하는 부분은 분리되지 않음
- 임계 구역 앞에 있는 것을 entry section, 뒤에 있는 것을 exit section이라고 함
- entry section : 필요한 세팅, 설정, 관계없는 일들을 모아둠
- exit section : 일부분, 임계 구역에 관련된 나머지 일들을 처리
- remainder section : 위와 관련 없는 나머지 일들을 하는 부분
Solution to Critical-Section Problem
- 상호 배제(Mutual Exclusion) - p1가 임계 구역에서 실행된다면 다른 프로세스들은 임계 구역에서 실행될 수 없다.(단 하나만)
- 진행(Progress) - 임계구역에서 실행되는 프로세스가 없는 상태에서 임계 구역으로 진입하려는 프로세스가 있으면 잔류 구역에서 실행되지 않고 있는 프로세스들만 다음에 임계 구역으로 진입할 수 있는 대상이 되고 이 구역은 무한하게 연기할 수 없다.
- Bounded Waiting(한계 대기) : 프로세스가 임계 구역으로의 진입을 요청한 후에 그 요청이 허용될 때까지 다른 프로세스들도 임계 구역에 진입하도록 허용하는 시간 간격에도 한계를 두어야 한다.(무한하게 대기하면 안 됨)
- 각 프로세스들은 무조건 대기하는 것이 아니라 진행되고 있어야 한다.

- P0, P1은 turn이라는 공유 변수를 가짐
- 만약 turn이 i다 라는 조건을 만족하면 임계 구역으로 들어갈 수 있음
- i = 0, j = 1
- Pi : turn값이 i와 다르면 무한루프 -> 처음에는 같기 때문에 critical section으로 들어감
- 끝난 후 turn을 j로 바꿈 -> 나머지를 수행 -> 반복
- Pj : i가 실행되는 동안 while문에서 대기 -> turn이 j가 되는 순간 탈출 -> 임계 영역에 들어감
- 두 프로세스가 동시에 진행된다면? -> i와 j값이 다르므로 어쨌든 하나는 대기, 하나는 실행됨
- 상호 대기 만족
- turn은 0으로 초기화되었는데, P1이 먼저 들어왔다면 P0이 들어오기 전까지 기다려야 하므로 진행(Progress)과 한계 대기(Bounded Waiting)를 만족하지 못함
- 반드시 번갈아서 진행되는 알고리즘이므로 하나의 프로세스 실행 후 다음 프로세스가 응답하지 않을 시 대기해야 한다.

- 플레그 2개를 선언함 -> flag[i]를 true, j를 flase로 정함
- Pj는 플레그가 flase이므로 while문을 통과하여 Pi가 실행됨 -> Pj가 응답하지 않더라도 계속 Pi가 실행될 수 있음
- Pj는 flag[i]는 ture일 때 임계 구역에 들어가지 못하고 대기 -> Pi가 실행된 후 flase가 되는 순간 Pj가 실행됨
- Pj가 실행되는 동안, Pi 역시 임계 영역에 들어가지 못함
- 번갈아서 실행할 필요가 없어짐
- 상호 배제 만족, 그러나
- 두 프로세스가 타이트하게 문맥 교환을 하는 경우
- 한 줄씩 번갈아가며 실행된다고 가정해보자
- flag를 각각 true로 바뀌면 두 플래그가 전부 true로 바뀐 후 while문에 접근하므로 두 프로세스 모두 대기
- 두 플레그 중 하나가 바뀌어야 프로세스 하나가 실행될 수 있음
- 마지막 알고리즘 - Peterson's Solution
- 앞의 두 가지의 문제를 잘 종합하여 둘 다 쓰면서 아무 문제없이 진행될 수 있음

- 프로세스가 하나씩 실행되는지
- 대기하는 경우가 발생하는지
- 타이트하게 문맥 교환이 이루어질 경우
'운영체제' 카테고리의 다른 글
| [14주차]철학자의 만찬&임계영역 프로그래밍&Deadlocks (0) | 2019.06.02 |
|---|---|
| [13주차]Bakery Algorithm (0) | 2019.06.01 |
| [11주차]간단한 어셈블리 프로그래밍 (0) | 2019.05.14 |
| [10주차]System Call의 이해 - 어세블리어 (PC버전) (0) | 2019.05.10 |
| Chapter 5 - CPU Scheduling(9주차) (0) | 2019.04.30 |