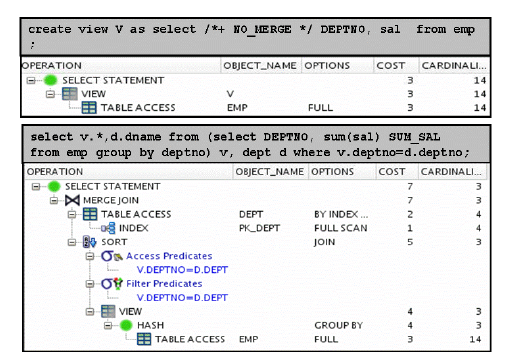
star transformation
- partition : 테이블, 인덱스 등을 파티션 단위로 나누어서 저장
- 관리상 장점 : 백업, 복구, 추가, 삭제 -> 작은 단위로 백업과 복구를 할 수 있게되어 용이
- 성능상 장점 : 파티션 단위로 조회, 병렬 -> 많은 데이터가 있더라도 작은 단위의 파티션만 읽어서 원하는 값을 얻을 수 있다면 성능이 훨신 좋아질 것
- 파티션 프루닝(pruning) -> 불필요한 파티션을 엑세스 하지 않고 필요한 파티션만 엑세스
- 파티션 와이즈 조인 -> emp 파티션, dept 파티션 둘 다 파티션 테이블이라면 둘을 조인할 때, 해당 파티션끼리만 조인을 할 수 있음
- 병렬처리를 할 수 있음 -> OLAP(분석) 과정에서 full scan을 할 때
- range 파티셔닝 : 파티션 키값의 범위에 따라서 각각의 파티션에 데이터를 저장
- hash 파티셔닝 : 해쉬함수를 이용해서 파티션 갯수만 정해주면 오라클서버가 알아서 데이터를 분배하는 방식
- list 파티셔닝 : 특정 파티션에 저장 될 데이터에 대한 명시적 제어가 가능
- index로 만들어진 클러스터 -> 인덱스가 반드시 필요, 인덱스 없이 데이터를 스캔 할 수 없음
- cluster index 필요 -> null 값을 가질 수 있음
- emp 와 dept를 조인한다고 가정
- emp_dept_clust 라는 빈 공간을 생성
- emp라는 테이블의 데이터와 dept라는 테이블의 데이터를 emp_dept_clust에 넣겠다고 선언
- ex) 10번 부서, accounting, NY 라는 dept 데이터 아래에 10번 부서에 근부하는 사원들의 데이터를 emp테이블에서 가져와 저장
- 부서를 배정받지 않은 사원이 있을 수 있으므로 cluster index에 null값이 존재
- 사용자는 어떤 방식으로 데이터가 저장되어 있는지 알 필요가 없음 -> 데이터의 투명성
- 단점
- 상대적으로 클러스터에서 읽는 데이터의 양보다 원래 테이블의 데이터 양이 더 적을 경우(parent 쪽을 읽을 경우)
- 저장 공간의 사이즈를 예측하여 만들어야 함 -> 총 몇개의 키, 들어갈 데이터가 한 블럭에 저장될지 등
- 만약 예측이 빗나가서 한 블럭 이상을 차지하게 된다면 overflow영역에 이어서 저장되어 i/o가 늘어남
- join된 형태의 데이터를 자주 사용할 경우 좋음
- 데이터를 넣을 때, hash함수에 먼저 넣어보고 나온 결과값에 데이터를 저장
- hashkeys : 몇 개의 hash key 값으로 저장을 할 것인지 -> ex) 2000개의 데이터 1000개의 해시 키, 1개의 동일한 해시 키에 2개의 데이터가 저장
- 데이터가 매우 많은 경우 찾기가 쉬움
- 데이터가 없더라도 예측한 만큼의 영역을 지정해 놔야 함
- 사이즈가 꽉 차서 넘어가면 overflow가 생김
- 재구축에 부담이 많음
- data - table(heap) - partition - cluster(hash, index) - IOT(index organized table)
- cluster 생성
- hash cluster 생성
- CREATE CLUSTER bigemp_cluster
- (deptno number, sal number sort)
- HASHKEYS 10000 single table HASH IS deptno SIZE 50
- tablespace users;
- hash cluster 적용
- create table bigemp_fact (
- empno number primary key,
- sal number sort,
- job varchar2(12) not null,
- deptno number not null,
- hiredate date not null)
- CLUSTER bigemp_cluster (deptno, sal);
- index cluster 생성
- CREATE CLUSTER emp_dept (deptno NUMBER(3))
- SIZE 600
- TABLESPACE users;
- index cluster 적용
- CREATE TABLE emp2
- ( empno NUMBER(7) ,
- ename VARCHAR2(15) NOT NULL,
- job VARCHAR2(9) ,
- mgr NUMBER(7) ,
- hiredate DATE ,
- sal NUMBER(7) ,
- comm NUMBER(7) ,
- deptno NUMBER(3))
- CLUSTER emp_dept (deptno);
- CREATE TABLE dept2
- ( deptno NUMBER(3) ,
- dname VARCHAR2(14),
- loc VARCHAR2(14),
- c VARCHAR2(500))
- CLUSTER emp_dept (deptno);
- cluster 테이블에 데이터의 위치를 관리할 index 생성
- CREATE INDEX emp_dept_index
- ON CLUSTER emp_dept
- TABLESPACE users;
- sort
- aggregate : 실제 sort가 아니라 그룹 함수를 사용했다는 의미
- unique : 중복 행 제거 -> union all -> sort 없음, union -> sort 있음
- join : merge join 진행
- group by, order by : group by한 결과를 sort까지 한 것
- hash
- group by : return된 데이터를 sort없이 group by 한 것
- unique
- buffer sort 연산자 : join 조건없음


- 동일한 equal 연산이 여러개(or) 일 경우 별도로 실행되어 결과가 순서대로 보여짐
- concatenation을 사용하면 sort되지 않고 뒤에서 앞으로의 순서로 결과가 보여짐
- /*+ use_concat(1) */

- Top-N query란? - from절의 inline view에 order by를 사용하는 것

- 첫 번째 줄만 읽어서 성능이 좋음
- 범위가 넓더라도 1줄의 결과가 나옴
- FILTER : 데이터를 filtering 하여 조건에 맞는 값만 걸러냄

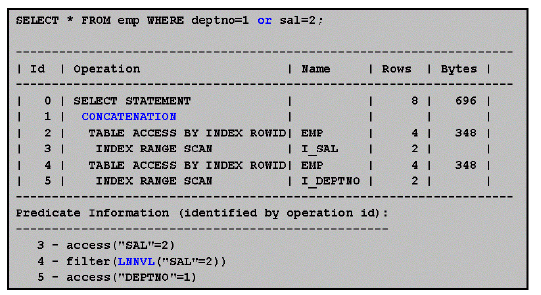
- 비교하고자 하는 두 컬럼 모두 index가 있는 경우 두 index를 다 씀
- LNNVL : 조건에 맞는 값이 오면 false
- union all 방식으로 변형
- select /*+ use_concat */ * from emp
- where job='ANALYST' or deptno=10;
- /*+ no_expand */ -> concatenation을 사용하지 않는 힌트
- /*+ use_concat(1) */ : 뒤에서 앞으로
- /*+ use_concat(8) */ : sort

- parsing 하기 전에 실행된 결과가 있는지 확인
- 이미 저장되어 있다면 cache에서 가져와서 출력
- DB level, Table level, 문장 level
- i/o가 일어나지 않음
- select /*+ RESULT_CACHE */ deptno, avg(sal)
- from emp
- group by deptno;
사례 연구 : Star Transformation

- DW 환경에서 사용 가능
- 사실값(fact) 테이블 : 분석하고자 하는 데이터가 한꺼번에 들어있음
- 차원(demension)/조회 테이블 : 어떤 제품인지, 어디서 판매되었는지, 고객 정보, 날짜 등 자세한 정보
- 예제

- 모든 조건에 sales가 들어감
- 행을 줄이기 어려움 -> where 절의 줄일 수 있는 조건들이 모두 demension


- demention의 조건을 서브쿼리로 변환 -> sales 테이블의 행을 줄일 수 있음
- 자동으로 바꿔줌

- bitmap 인덱스 생성 후 연산

- 줄인 행들을 가지고 조인
- 결과 출력
- 조인할 데이터의 양이 줄어듦
- 비트 방식 작업을 제거하는데 사용
- 사용되는 조인 인덱스가 이미 사전 계산되어 있는 경우 조인해야 하는 데이터의 양을 줄일 수 있음
- 조인 인덱스에 차원 테이블이 여러 개 포함되어 있으면 기존 비트맵 인덱스를 사용하는 star transformation에 필요한 비트 방식 작업이 제거될 수 있음






- 차원 테이블의 카테고리를 만들 수 있음 -> 세분화
- 차원 테이블이 가지를 뻗어 나가는 형태
옵티마이저 통계
- 객체 통계 : table, column, index
- 시스템 통계
- 수동
- 자동
- analyze table emp2 compute statistics; -> empty_blocks, avg_space, chain_cnt 정보는 dbms_stats로는 수집되지 않음
- exec dbms_stats.gather_table_stats('USER01','EMP3');
- chain_cnt : migration 된 행의 개수 + chain 된 행(한 블럭에 한 행이 모두 저장되지 못해 다른 블럭에 이어서 저장)의 개수
