- 같은 문장에 바인드 변수 사용
- 상수를 사용
- 바인드 변수 피킹 - 처음 데이터를 넣었을 때만 parsing하고 다음 데이터들 부터는 첫번째 실행계획을 사용
- 검증된 실행계획을 저장
- SQL 계획 Baseline

- 첫 번째 실행계획이 baseline에 저장
- 새로운 실행계획이 만들어져도 실행시키지는 못하고 baseline에 있는 실행계획을 사용
- 검증과정을 거쳐서 다른 실행계획이 검증된다면 baseline에 넣어줌 -> 기존에 저장되어 있던 계획도 그대로 사용
- baseline 안의 실행계획들중 어떤 것을 사용할지 cost를 계산하여 사용

- ACC - baseline에 저장되었는지
- FIX : 사용중인 실행계획인지
SQL Tuning Advisor
- 통계를 만듦
- SQL을 튜닝하여 최적의 실행계획을 찾아냄
- 찾아낸 실행계획을 프로파일로 저장 -> 힌트, 통계의 집합
- 프로파일을 적용하면 성능이 좋아짐
- 인덱스를 만듦 - create index
- 누락된 index 추가 -> access advisor 실행
- SQL 재구성
- 데이터가 제한되게 보임 -> 보안성
- 일부의 데이터 뷰를 만들어 놓고 그 범위 내에서만 조회 가능하도록 권한을 줌
- refresh를 시키는 방법
- complete : 전체를 refresh
- fast(log) : log만 반영
- Materialized View를 생성할 때, 사용했던 select 문을 조회해도 table이 아닌 view를 읽어옴 -> query rewrite
- sql 문장의 의미를 이해하기 편해짐
- 한 번만 기술 하여 사용함으로써 가독성이 좋음
- 저장된 내용을 사용하기 때문에 좋은 성능을 가짐
- 문장 실행시 가장 먼저 실행됨
- over(partition by deptno) : 부서별로 묶어서 처리 - ex) 부서별 누적



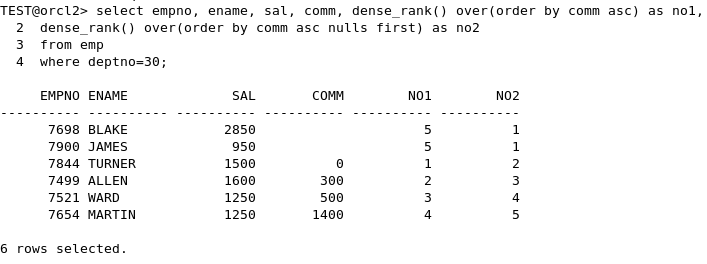
- rank() 함수는 공동 순위를 매기고 그만큼 다음 순위를 밀어냄
- dense_rank() 함수도 공동 순위를 매기지만 그 다음 순위는 그대로 +1
- 부서 내에서 순위를 매길 수 있음

- 행들의 그룹 : window
- 행들의 그룹들 중 제한해서 보여줌
- rows 와 range 가 있음
- rows는 물리적, range는 논리적

- window의 범위를 앞, 뒤 한 줄씩으로 지정 - rows between 1 preceding and 1 following
- sum(sal)을 앞, 뒤의 값만 수행
- unbounded preceding and current row - 계속 누적 그냥 over과 동일


- 기준이 되는 column의 범위(여기서는 -100 ~ +100)내의 값들을 사용
- sum(sal)이므로 앞, 뒤로 100이 차이나는 범위의 empno를 가진 사원들의 sal을 sum
- order by 시에 null값을 어떻게 할 것인가
 sal값이 2900이면 emp 테이블의 sal값들 중 몇 번째 일 것인지 출력
sal값이 2900이면 emp 테이블의 sal값들 중 몇 번째 일 것인지 출력
- 분석함수는 where보다 나중에 수행되므로 select절에 사용할 경우 잘못된 값이 나올 수 있음, 따라서 from절에서 inline view를 사용해야 함
- LAG 함수와 LEAD 함수
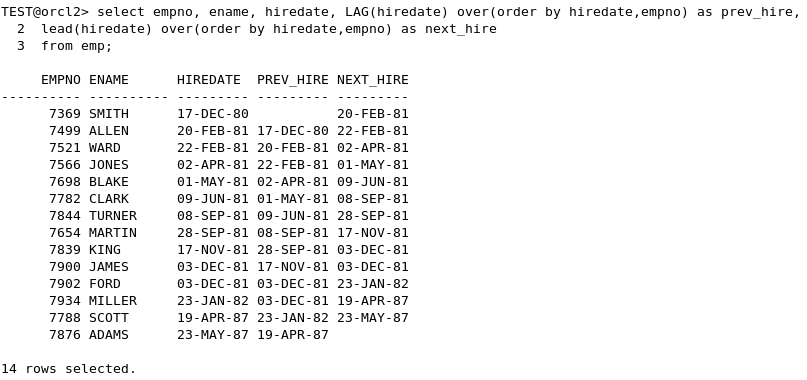
- 바로 직전에 입사한 선임과 바로 이후에 입사한 후임을 알 수 있음
- 위와 같이 선임의 입사 날짜, 후임의 입사 날짜를 확인 가능

- 조건에 일치하는 컬럼의 값들을 한줄에 출력
- 여러 행으로 나온 컬럼들을 한 컬럼으로 출력


- 전체 비율(100%) 중 어느정도를 차지하고 있는지를 보여줌
- over안에 partition by를 사용하면 그룹으로 묶은 값들의 총 합 중 어느정도를 차지하는지 보여줌

- 전체를 등분하는 함수
- NTILE(5) over(order by sal desc) : sal을 내림차순 한 것을 5등분하여 숫자를 매김
- CUME_DIST(cumulative distribution) / PERCENT_RANK
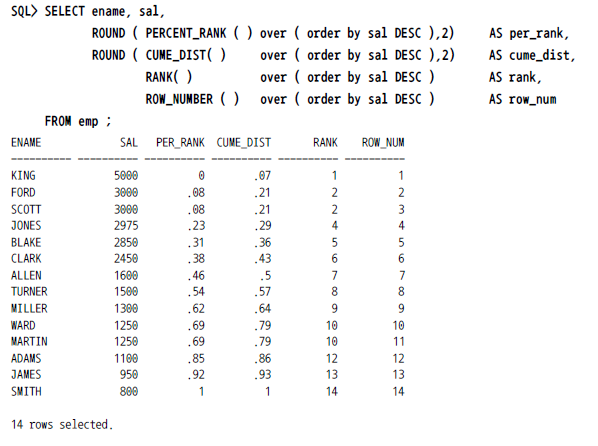
- percent_rank : (rank-1)/(count(*)-1)
- cume_dist : (rank or row_number) / count(*)
읽기 일관성
- ACUD - 원자성, 일관성, 격리성, 영속성
- 원자성 : 쪼개질 수 없는 단위
- 일관성 : 데이터를 읽는 읽기 일관성
- Dirty read : commit이 안된 데이터를 읽는 것 - Read uncommited
- Non repeatable read : 한 트랜잭션 내에서 두 번의 쿼리를 수행했는데 수정된 다른 값이 검색되는 것 -> 트랜잭션 레벨의 읽기 일관성을 사용(시작과 끝을 지정)
- Phantom read : select를 여러번 한 결과가 다름 -> insert 되었기 때문
- read commited : commit된 결과만 읽음 -> 문장이 실행 될 때마다 커밋이 되었는지 확인(dirty read 방지)
- repeatable read : commit을 했으나 예전 데이터를 읽을 수 있음 -> dirty read 방지, non repeatable 방지
- serializable read : dirty read 방지, non repeatable 방지, phantom reads