정규화(Normalization)
- 정규화란 논리적 설계 단계에서 발생할 수 있는 종속으로 인한 이상(Anomaly) 현상의 문제점을 해결하기 위해, 속성들 간의 종속 관계를 분석하여 여러 개의 릴레이션으로 분해하는 과정을 말한다.
- 정규화된 결과를 정규형이라고 하며, 정규형의 종류로는 제1정규형, 제2정규형, 제3정규형, BCNF, 제4정규형, 제5정규형 등이 있다.
- 정규형의 종류
- 제1정규형(1NF : First Normal Form) : 한 릴레이션을 구성하는 모든 도메인이 원자 값(Atomic Value)만으로 구성되도록 하는 정규형을 말한다.

- 위 사진을 보면 한 회원이 하나 이상의 수강과목을 수강하고 있으므로 원자값을 가지도록 테이블을 분해해야 한다.
- 따라서 회원번호를 기본키로 가진 회원(회원번호, 성명, 연락처) 테이블과 수강과목을 기본키로 가진 강좌(수강과목, 수강료) 테이블로 분해한다.
- 아래 사진처럼 분해한 후 수강과목을 외래키로 하여 참조 관계로 사용하면 된다.

- 제2정규형(2NF : Second Normal Form) : 제1정규형을 만족하면서 릴레이션을 구성하는 모든 속성이 기본키에 완전 함수 종속이 되도록 분해하는 과정을 말한다. 즉, 부분 함수 종속을 제거하고 모든 속성이 기본키에 완전 함수 종속이 되도록 한다.

- 위 사진처럼 고객번호와 제품번호가 합성키(복합키)로써 주문량을 알 수 있는 기본키가 된다.
- 그러나 제품명은 제품번호만 알아도 알 수 있으므로 이는 부분 함수 종속관계에 있다.
- 부분 함수 종속 관계를 제거하는 정규화 과정이 2NF이다.
- 아래 사진처럼 주문량(고객번호, 제품번호, 주문량) 테이블과 제품(제품번호, 제품명) 테이블로 나눈다.

- 제3정규형(3NF : Third Normal Form) : 제2정규형을 만족하면서 이행적 함수 종속 관계를 분해하여 비이행적 함수 종속이 되도록 하는 과정을 말한다.

- 위 사진을 보면 학번을 알면 전공을 알 수 있고 전공을 알면 담당교수를 알 수 있으며 학번을 알면 담당교수를 알 수 있다.
- 이행적 함수 종속은 학번 -> 전공, 전공 -> 담당교수 일 때, 학번 -> 담당교수인 경우를 말한다.
- 이행적 함수 종속을 없애는 과정이 제3정규화이다.

- 보이스-코드 정규형(BCNF : Boyce-Codd Normal Form) : 제3정규형을 만족하면서, 릴레이션에서 모든 결정자가 후보키가 되도록 하는 과정을 말한다.

- 후보키 : 각 튜플을 유일하게 식별할 수 있는 속성이나 속성의 집합(튜플마다의 고유한 속성)
- 2NF와 다른 점 : 2NF에서는 복합키 안의 일부만 알아도 알 수 있는 속성이 있었지만 BCNF에서는 완전히 복합키로만 식별할 수 있게 되어있다.(부분 함수 종속 관계가 없다.)
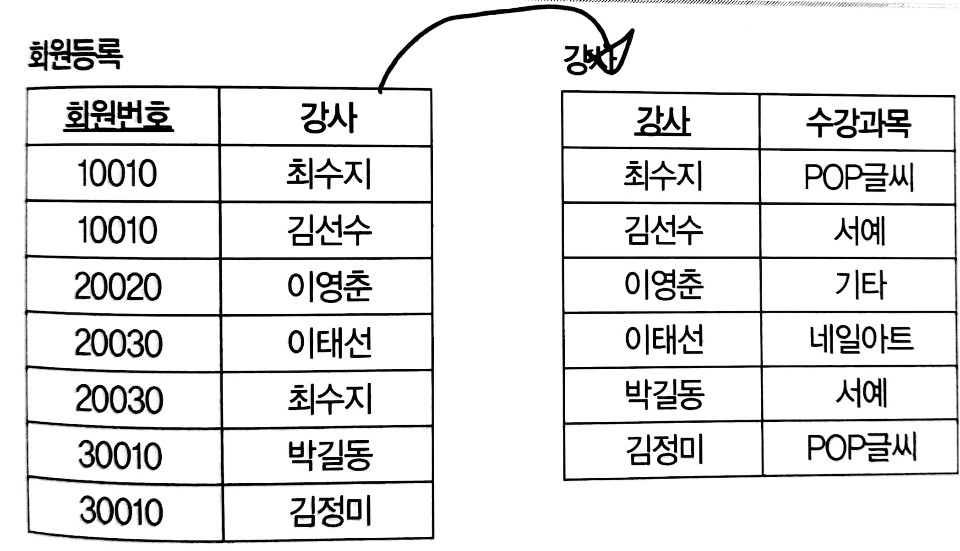
- 위 사진에서 회원번호와 수강과목은 복합키로써 기본키의 역할을 한다. (회원번호, 수강과목) -> 강사
- 한 회원이 여러 수강과목을 신청할 수 있으므로 회원번호 하나만으로는 후보키가 될 수 없다.
- 또한 같은 수강과목에도 강사가 여러 명이 존재하므로 수강과목 하나만으로 후보키가 될 수 없다.
- 강사는 후보키가 아님에도 불구하고 수강과목을 결정하는 결정자이다. 강사 -> 수강과목
- 이와 같이 결정자가 후보키가 아닌 테이블을 분해하는 과정이 BCNF이다.
- 아래 사진처럼 회원등록(회원번호, 강사) 테이블과 강사(강사, 수강과목) 테이블로 분해한다.
- 제4정규형(4NF : Fourth Normal Form) : 다치 종속(MVD : Multivalued Dependency) 관계가 성립되는 경우 분해하는 정규형을 말한다.

- 다치 종속 관계란 위의 사진처럼 모든 함수 종속 관계는 성립되지 않지만 한 속성이 다른 속성의 집합을 알 수 있는 경우를 의미한다. (과목명을 알면 강사들을 알 수 있고 마찬가지로 과목명을 알면 교재들을 알 수 있다.
- 표시 방법 : 과목명 ->-> 강사, 강사 ->-> 교재
- 다치 종속 관계의 테이블을 분해시키는 것이 제4정규형(4NF)이다.
- 아래 사진처럼 강사(과목명, 강사) 테이블과 교재(과목명, 교재) 테이블로 나눈다.

- 제5정규형(5NF : Fifth Normal Form) : 조인 종속(Join Dependency)이 후보키를 통해서만 성립이 되도록 하는 정규형을 말한다.
- 조인 종속(Join Dependency) : 원래의 릴레이션을 분해한 뒤 자연 조인한 결과가 원래의 릴레이션과 같은 결과가 나오는 종속성
'정보처리기사 실기 > 데이터베이스' 카테고리의 다른 글
| [2019/06/25] 데이터베이스 개념 공부 (0) | 2019.06.25 |
|---|---|
| [데이터베이스 기출 개념]2017년 3회 (0) | 2019.06.22 |
| [데이터베이스 기출 개념]2018년 1회 (0) | 2019.06.20 |
| [데이터베이스 기출 개념]2018년 2회 (0) | 2019.06.19 |
