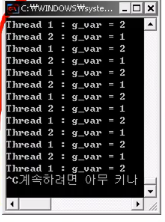
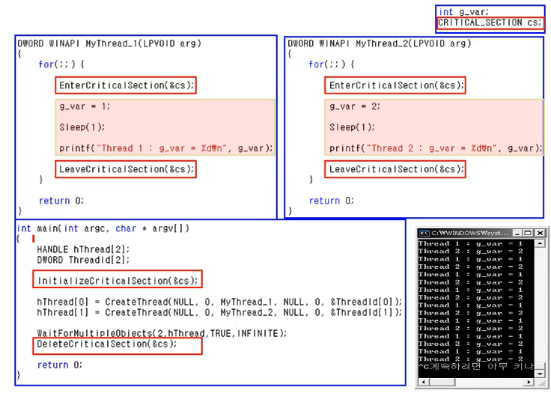
- 내가 만든 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
|
#include <Windows.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define T_MAX_SIZE 10
#define C_MAX_SIZE 50
HANDLE hMutex;
HANDLE Rsemaphore;
HANDLE Csemaphore;
LPCTSTR Restaurant;
LPCTSTR Clean;
int N = 1;
int Alltime = 0;
int group;
int Cleantime = 3;
int exitcnt = 0;
DWORD WINAPI C_Number(LPVOID CTime)
{
int GN = group;
WaitForSingleObject(Rsemaphore, INFINITE);
int eat = (int)CTime;
int Num = 0;
int before = Alltime;
Num = N++;
if (eat == 0) {
printf("%d번째 그룹(%d명) Take Out\n\n", Num, GN);
}
else {
printf("%d번째 그룹 입장(%d명), 입장시간 : %d분, 소요시간 : %d분\n\n", Num, GN, before, eat);
Sleep(eat * 100);
before += eat;
printf("%d번째 그룹 퇴장\n\n", Num);
WaitForSingleObject(Csemaphore, INFINITE);
before += Cleantime;
printf("종업원이 %d번째 그룹이 사용한 테이블을 청소하는 중입니다.\n\n", Num);
Sleep(Cleantime * 100);
printf("%d번째 그룹이 사용한 테이블 청소 완료!\n\n", Num);
ReleaseSemaphore(Csemaphore, 1, NULL);
}
Alltime = before;
ReleaseSemaphore(Rsemaphore, 1, NULL);
return 0;
}
int main(int argc, char*argv[])
{
srand(time(NULL));
int C_Eatting_Time;
int Alleat = 0;
int Gcnt = 0;
int employee = 0;
int Maxgroup = 0;
int pack = 0;
printf("한 테이블당 최대로 앉을 수 있는 손님의 수를 입력해주세요 : ");
scanf_s("%d", &Maxgroup);
printf("종업원의 총 수를 입력해주세요 : ");
scanf_s("%d", &employee);
HANDLE hThread[C_MAX_SIZE];
DWORD ThreadId[C_MAX_SIZE];
Rsemaphore = CreateSemaphore(NULL, 10, T_MAX_SIZE, Restaurant);
Csemaphore = CreateSemaphore(NULL, employee, employee, Clean);
hMutex = CreateMutex(NULL, FALSE, NULL);
for (int number = 0; number < C_MAX_SIZE; number += group) {
pack = rand() % 101;
group = (rand() % Maxgroup) + 1;
C_Eatting_Time = (rand() % 21) + 10;
if ((number + group) > C_MAX_SIZE) {
group = C_MAX_SIZE - number;
}
if (pack <= 30) {
C_Eatting_Time = 0;
hThread[Gcnt] = CreateThread(NULL, 0, C_Number, (LPVOID)C_Eatting_Time, 0, &ThreadId[Gcnt]);
}
else {
Alleat += C_Eatting_Time;
hThread[Gcnt] = CreateThread(NULL, 0, C_Number, (LPVOID)C_Eatting_Time, 0, &ThreadId[Gcnt]);
}
Gcnt++;
Sleep(1);
}
WaitForMultipleObjects((Gcnt - 1), hThread, TRUE, INFINITE);
printf("식당이 영업을 한 시간 : %d분\n\n", Alltime);
printf("손님들의 평균 식당 이용 시간 : 약 %d분\n\n", (Alleat / (Gcnt - 1)));
return 0;
}
|
cs |
- 포장할 확률을 30%로 설정
- 이전과 마찬가지로 난수를 발생시켜 30이하로 발생하면 포장, 그 이후로는 원래대로 동작
- 포장을 하는 경우는 식당 이용시간을 0으로 생각
- 결과 동영상
- 포장을 할 수 있게 만들었더니 처리 시간이 더욱 빨라짐
'레스토랑 시뮬레이션' 카테고리의 다른 글
| [레스토랑 시뮬레이션]일행&종업원 추가 (0) | 2019.06.09 |
|---|---|
| [레스토랑 시뮬레이션]총 처리시간과 평균 이용시간 (0) | 2019.06.08 |
| [레스토랑 시뮬레이션] 기본 코드 (0) | 2019.06.08 |