시분할 시스템(Time-shared systems)은 사용자 프로그램이나 태스크(tasks)를 수행
우리가 배우는 운영체제 과목에서는 작업, 프로세스, 태스크 모두 같은 것으로 봄
프로세스란? - 간단하게 수행, 실행 중인 프로그램
실행 중이지 않은 프로그램은 저장되어 있는 프로그램 -> 보조기억장치에 저장(디스크)
운영체제 입장에서 프로세스는 로딩(적제)되어 메인 메모리를 차지하고 동작하고 있거나 바로 직전인 상태(수행)
순차적인 방식(sequential fashion) : 하나씩 정해진 순서대로 실행되어야 함
수행 중인 프로그램은 우리 눈에 보이는 소스 프로그램이나 소스 프로그램이 바뀐 코드 형태 자체만은 아님(부분)
프로세스란 단순히 프로그램 그 자체를 의미하는 것이 아니라 다음을 포함한 능동적인 실체이다.(환경까지 모두)
Program counter
stack
data section
레지스터
프로그램 코드
ex) 프로그램 코드 실행 -> 실행되는 동안 생성된 데이터들이 저장됨(스택이나 데이터 섹션) -> CPU가 가지고 있는 변화되는 값들이 레지스터에 저장 -> 많은 코드 중 어느 위치에서 실행하는지에 대한 프로그램 카운터
위의 항목에 다른 것들을 추가한 것을 프로세스 컨트롤 블록이라 한다.
Process in Memory
text : 코드와 상수 값들이 들어감, 프로그램이 실행되면 정해진 만큼만 가질 수 있음
stack, heap : 변화되는 공간
stack은 높은 번지에서 낮은 번지로 내려오고 heap은 낮은 번지에서 높은 번지로 올라감
그렇게 되면 파란색 공간이 버퍼링 공간이 되어 stack과 heap 둘 다 될 수 있음
overflow도 될 수 있음
Memory Layout of a C Program(C프로그램에서는 메모리에 어떻게 배치되고 설정이 되고 동작이 되는지)
x값과 y값이 data에 저장됨
메인 함수 안에 변수 2개는 지역변수, stack에 저장
value에 int형태로 메모리를 할당
처음 실행파일을 실행할 때, 메인에 값을 줌(커멘드 창에서)
비주얼 스튜디오에서 환경변수를 주는 설정을 사용하여 줄 수도 있음
argc는 입력하는 값들의 수, argv는 입력한 값들을 순차적으로 저장
전역 변수는 data영역으로 - 시스템마다 다를 수 있지만 여기서는 분리되어 저장됨, 0으로 초기화되어 저장될 수도 있음 -> 어떤 환경인지 체크하여 방식을 달리 함
main함수의 argment들은 가장 위에 저장
로컬 변수(지역 변수)는 stack영역으로 - 어떤 시스템도 초기화하지 않는 변수
value는 포인터이기 때문에 가리키는 주소는 stack에, 할당한 20바이트는 heap영역에 저장된다.
예제
rose라는 텍스트 자체는 텍스트에 저장되고 읽기만 할 수 있음
a안에 r, o, s, e값이 각각 하나씩 배열로 저장되고 마지막에 NULL값이 저장 총 5개(가변 x)
p는 지역 변수에 포인터 stack에 저장-> grace라는 값을 가리킴(text에 저장되어 있음)
b []도 지역 변수이지만 포인터가 아닌 배열. 역시 stack에 저장(stack에 text값 복사)
따라서 b의 값은 stack에서 얼마든지 바꿀 수 있지만, p의 값은 바꿀 수 없다.
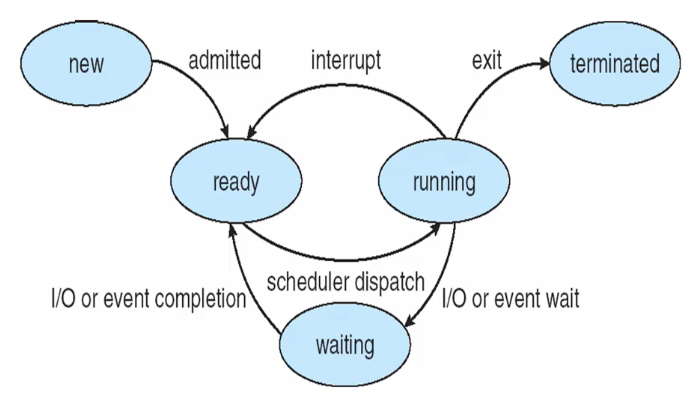
Process state
프로세스는 실행되면서 자신의 상태가 계속 변하게 됨
new : 모든 프로세스는 만들어지는 과정이 필요. 만들어진 후의 상태
running : CPU를 차지하고 있는 상태. 동작중인 상태
waiting : 기다리는 상태. CPU를 차지하기 위한 것이 아니라 외부 입출력(I/O)을 기다리는 상태. 따라서 CPU를 사용하지 않음
ready : 동작하려 하고 있으나 아직 CPU를 차지하지 않은 상태. 기다림
terminated : 프로세스가 모드 끝난 상태
프로세스가 생성된 후 실행되기 전까지 ready -> CPU를 차지하고 running -> 실행이 끝났으면 terminated -> I/O를 기다려야 한다면 waiting -> 적당한 시간을 두어 끝나지 않는다면 다시 ready로 돌아가 다른 프로세스와 CPU를 차지하기 위해 경쟁하며 끝날 때까지 반복됨
Process Control Block(PCB)
각 프로세스는 운영체제에서 프로세스 제어 블록(PCB)에 의해 표현된다.
프로세스의 컨텍스트가 만들어지고 그것들 끼리의 교환이 이루어짐
프로세스 상태(Process state) : 생성, 준비, 수행, 대기, 정지 상태
프로그램 카운터(Program counter) : 다음에 실행될 명령어의 주소
CPU 레지스터(CPU registers) : CPU 레지스터는 컴퓨터 구조에 따라 다양한 수와 형태를 갖는다.(다른 작업으로 넘어가기 전에 모든 상태를 저장)
CPU 스케줄링 정보(CPU scheduling information) : 프로세스 운선 순위, 스케줄 큐의 포인터와 다른 스케줄 매게 변수들을 포함
메모리 관리 정보(Memory-management information) : 기준과 한계 레지스터의 값, 운영체제가 사용하는 기억장치 시스템의 페이지 테이블 또는 세그먼트 테이블의 정보를 포함
계정 정보(Accounting information) : CPU가 사용된 실시간의 양, 시간 범위, 계정 번호, 작업 또는 프로세스 번호를 포함
입출력 상태 정보(I/O status information) : 입출력 요구들, 입출력 장치들과 open된 파일의 목록 등을 포함
이 PCB는 프로세스와 프로세스간의 스위칭에 이용된다.
CPU Switch From Process to Process
2개의 프로세스(P0, P1)이 있는데, P0가 실행되는 중에 P1으로 바뀌는 경우의 그림
P1이 실행된 후 다시 P0로 돌아가서 실행
화살표는 실행된다는 의미, 나머지 검은 선은 쉬고있다는 의미
상태를 저장하지 않는다면 다시 돌아왔을때, 중간부터 실행하지 못함 -> PCB에 상태 저장
P1의 상태를 불러와서 program counter의 위치부터 실행
P1에게 주어진 시간이 다 되었거나 모든 실행이 끝났다면 다시 현재 상태를 PCB에 저장한 후 P0의 상태를 불러옴
저장하는 시간과 불러오는 시간이 있으므로 딜레이가 생길 수 있음 -> 이 때는 어느 프로세스도 실행하지 못함
번갈아서 실행이 되지만 동시에 실행되는 것처럼 보임 -> iIde시간과 스위칭하는 시간을 줄이는 것이 좋음
이를 context switching이라고 부른다.
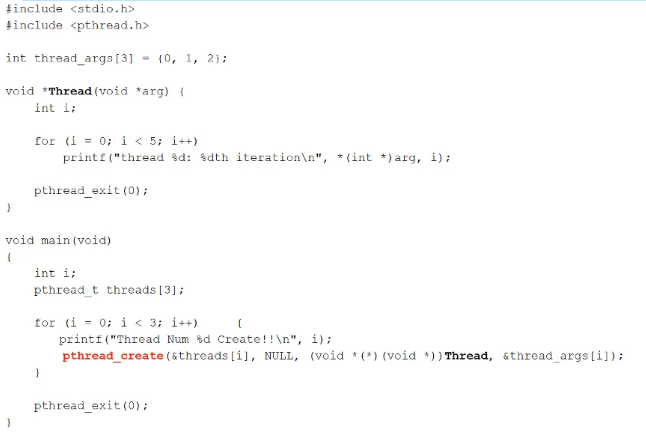
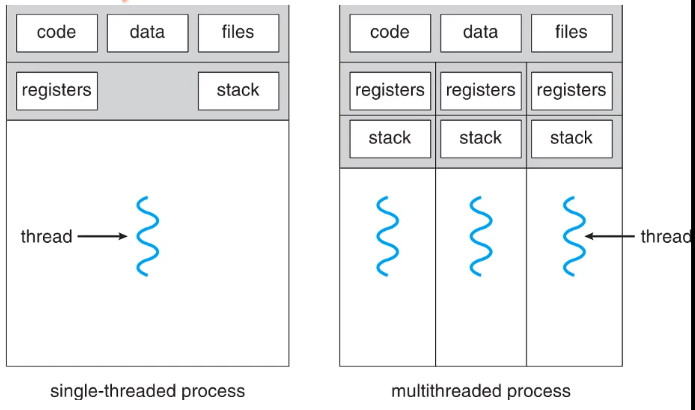
Threads
프로세스를 이루고 있는 실행단위
하나의 프로세스안에 여러 쓰레드를 둘 수 있음
Process Representation in Linux
Process Scheduling
프로세스들의 우선순위를 정해서 CPU를 차지 할 수 있도록 하는 것
가장 기본적인 방법인 queue를 사용
ready queue : CPU를 차지하기 위해 대기하고 있는 프로세스들
wait queues : I/O장치를 쓰기위해 대기하고 있는 프로세스들
Device queues : 디바이스들을 기다리고 있는 각각의 프로세스들
Ready and wait Queues
처음에는 head만 있음
queue라고 해서 순서가 있는 것이 아님
모여있는 것들 중 하나를 스케줄링해서 필요한 것을 CPU에 할당
Representation of Process Scheduling한 프로세스가 CPU를 차지하고 돌아가는 과정
ready queue에서 CPU를 할당받아 실행됨
실행이 끝났다면 그냥 종료하면 되지만 끝나지 않고 시간이 만료됐다면 다시 ready상태로 돌아가 우선순위를 스케줄링 -> I/O 요청, 시간 만료, 자식프로세스 fork, 인터럽트를 받아 대기 등
Schedulers
단기 스케줄러 : 실행 준비가 되어 있는 프로세스들 중에 하나를 선택하여 CPU에 할당(ready queue)
장기 스케줄러 : 프로세스를 선택하여 실행하기 위해 기억장치로 적재
new로 만들어지면 ready queue로 가서 단기 스케줄러에 의해 CPU를 할당받음
이 범위를 넘어가는 시스템이 존재 -> 서버 : 사용자 요청이 오면 프로세스를 각자 생성하기 때문에 사용자의 수가 많을 수록 엄청난 양의 프로세스가 생성됨
단기 스케줄러로 많은 양을 처리하기에 부담
ready queue로 갈지 말지 판단해주는 역할 -> ready queue에 부담이 가지 않도록 관리
장기 스케줄러는 단기 스케줄러가 효율적으로 작동할 수 있도록 도와줌
Addition of Medium Term Scheduling(장기와 단기의 중간)
time sharing 시스템을 가지는 일부 운영체제들은 medium term scheduler를 가짐
장기 스케줄러는 가지지 않고 단기 스케줄러만 가짐
프로세스가 많아지는 경우 임시로 우선순위가 떨어지거나 자주 사용하지 않거나 접근한 시간이 없는 프로세스들을 외부로 보냄(swap out)
밖에서 실행되도록 함
swap in : 밖에서 실행되는 프로세스를 다시 불러오는 것
Context Switch(문맥 - 프로세스가 진행되는 흐름)
프로세스의 흐름을 멈춘 후 다른 프로세스를 실행 했다면 다시 원래 상태로 돌아왔을 때, 실행됐던 흐름부터 시작할 수 있도록 해줌